~50%
reduction in total ML inferencing costs for Samsara
240,000
cores for model serving deployed with Ray Serve at Ant Group
up to
60%
higher QPS serving with optimized version of Ray Serve (vs. open source Ray Serve)
up to
50%
fewer nodes with features like Replica Compaction (compared to open source Ray)
What is Ray Serve?
Ray Serve is a scalable model serving library for building online inference applications, offering features like model composition, model multiplexing, and built-in autoscaling.
Because Ray Serve is framework-agnostic, you can use a single toolkit to serve everything from deep learning models built with any ML framework, including PyTorch, TensorFlow, and other popular frameworks.
Plus, Ray Serve has several features and performance optimizations for serving LLMs such as response streaming, dynamic request batching, multi-node/multi-GPU serving, and more.
Ray Serve Feature Highlights
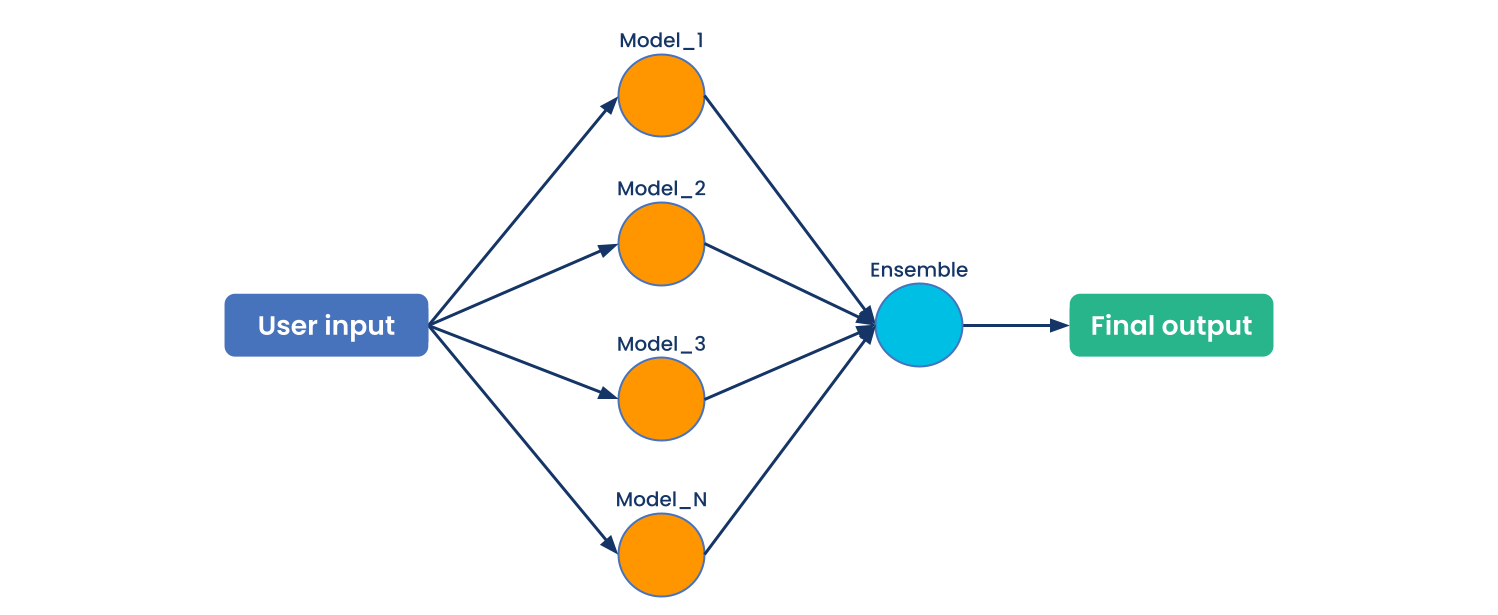
Model Composition
Integrate multiple ML models with separate resource requirements and auto-scaling needs within one deployment. Orchestrate processing workflows at scale with Ray Serve.
Supercharge Ray Serve with Anyscale




Feature Comparison
Runtime: Performance and Cost
Scale from your laptop to 1,000s of nodes easily



Production Readiness
Production services support for model training and deployment
Cloud and GPU Support
Launch Your Cluster on Any Cloud with Any Accelerator
Many Model Patterns
Support
Support led by the creators and maintainers of Ray
| | | |
|---|---|---|---|
Runtime: Performance and CostScale from your laptop to 1,000s of nodes easily | N/A | – | |
Production ReadinessProduction services support for model training and deployment | | Limited | |
Cloud and GPU SupportLaunch Your Cluster on Any Cloud with Any Accelerator | N/A | Limited | |
Many Model Patterns | Limited | | |
SupportSupport led by the creators and maintainers of Ray | — | Limited | |
Out-of-the-Box Templates & App Accelerators
Jumpstart your development process with custom-made templates, only available on Anyscale.
Deploy LLMs
Base models, LoRA adapters, and embedding models. Deploy with optimized RayLLM.
Deploy Stable Diffusion
Text-to-image generation model by Stability AI. Deploy with Ray Serve.
Ray Serve with Triton
Optimize performance for Stable diffusion with Triton on Ray Serve.

FAQs
Anyscale is the smartest place to host Ray, providing a managed experience that increases performance, optimizes utilization, and reduces costs. Anyscale improves Ray Serve runtime and scalability with advanced features like:
- Multi-AZ serve
- Replica compaction
- Optimized runtime
- Fast autoscaling (launch 1000+ nodes in 60 seconds or less)
- Unified log viewing and observability
- Serverless pools
- And much more!